Which attribution model is right for you? It depends on your data, goals, and the complexity of your customer journeys. Deterministic attribution gives precise, user-level tracking when identifiers like email addresses or logins are available. Probabilistic attribution estimates touchpoint contributions using statistical patterns, making it ideal for fragmented, privacy-focused environments.
Here’s what you need to know:
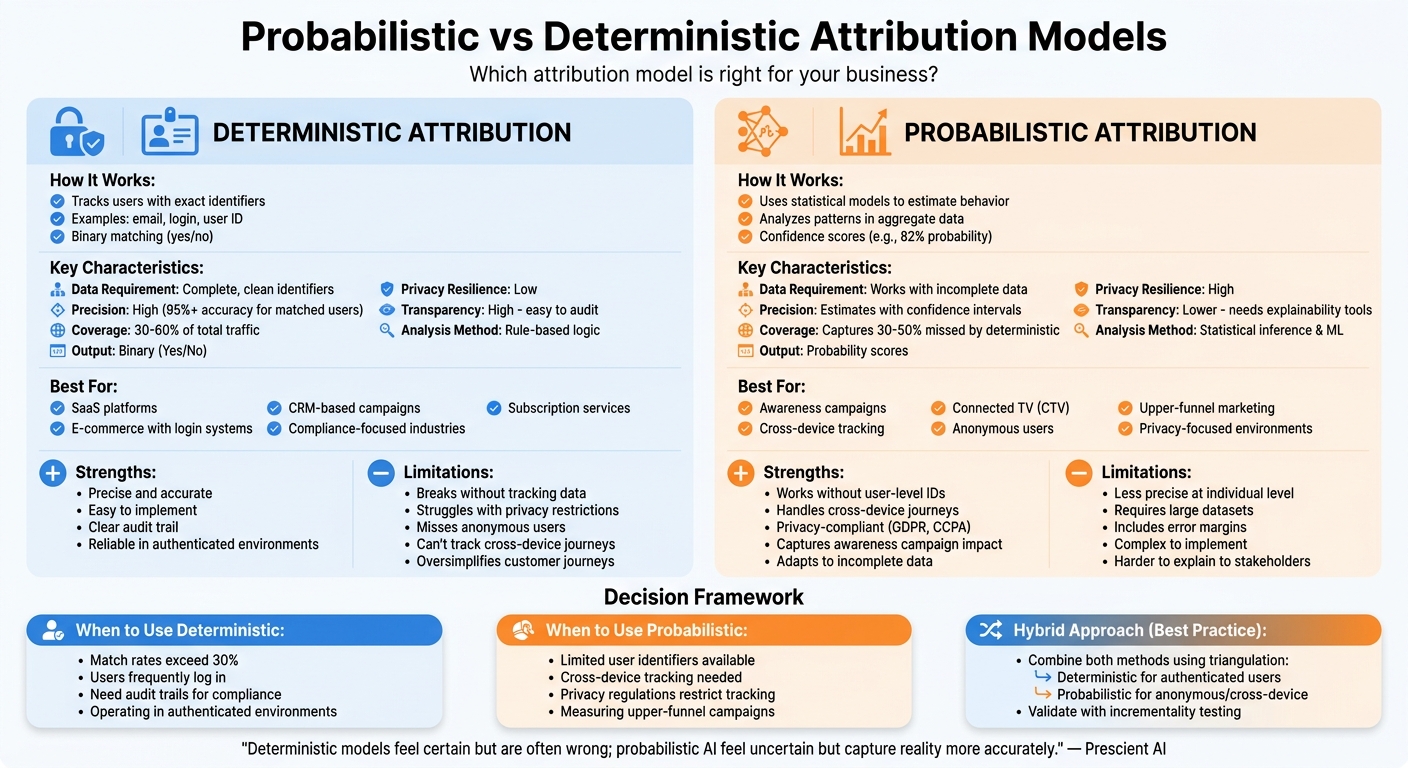
- Deterministic Attribution: Tracks users with exact identifiers (e.g., email, login). It’s precise and transparent but struggles with privacy restrictions and untracked touchpoints.
- Probabilistic Attribution: Uses statistical models to estimate behavior. It works well for anonymous users, cross-device tracking, and awareness campaigns but introduces margins of error.
Key Differences
| Factor | Deterministic Attribution | Probabilistic Attribution |
|---|---|---|
| Data Needs | Complete identifiers | Works with incomplete data |
| Precision | High | Estimates with confidence scores |
| Privacy Resilience | Low | High |
| Best For | CRM-based campaigns, e-commerce | Awareness campaigns, cross-device tracking |
Takeaway: Deterministic models are great for exact tracking in authenticated environments, while probabilistic models provide broader insights where data is fragmented. A hybrid approach often works best.
Probabilistic vs Deterministic Attribution Models Comparison
How Deterministic Attribution Works
Core Mechanism
Deterministic attribution relies on matching consistent identifiers across different touchpoints to track users. These identifiers include hashed email addresses, login credentials, user IDs, device IDs (like Apple’s IDFA or Google’s GAID), and first-party cookies. For example, if a user clicks on an ad while logged in and later makes a purchase under the same hashed email, the system links these actions directly.
"Deterministic attribution is exact when identity is present. If a logged-in user clicks an ad and completes a purchase under the same hashed email, the match is binary: Either it is the same user, or it's not." – Fusepoint Insights
Credit in deterministic attribution is assigned based on predefined rules. In a last-click model, for instance, the ad clicked immediately before the conversion gets full credit. This method thrives in environments where user identity can be verified, offering highly accurate tracking.
Strengths of Deterministic Attribution
The standout feature of deterministic attribution is its accuracy. When identifiers are in place, it delivers precise and consistent results. This makes it especially useful in environments like SaaS platforms, e-commerce sites with loyalty programs, or subscription-based services where users are often logged in.
Another key advantage is its transparency. Because the user’s journey from initial touchpoint to conversion is mapped through verified identifiers, marketers gain a clear view of the entire process. This is particularly beneficial for campaigns tied to CRM data, such as sales or retention efforts, where user identity is already established.
Limitations of Deterministic Attribution
Despite its strengths, deterministic attribution has some clear challenges. It becomes ineffective when a user’s identity is no longer identifiable. For instance, if someone clears their cookies, switches devices, or browses without logging in, the tracking chain breaks.
Privacy regulations and platform updates also pose hurdles. With Apple’s iOS 14.5 update, users can opt out of tracking through App Tracking Transparency, while the deprecation of third-party cookies and stricter laws like GDPR and CCPA have further reduced tracking capabilities.
Another limitation is its inability to account for awareness campaigns. Interactions like podcast sponsorships, top-of-funnel video ads, or other non-click engagements may influence user behavior but leave no direct, trackable trail.
sbb-itb-d1a6c90
How Probabilistic Attribution Works
Core Mechanism
Probabilistic attribution relies on statistical estimation rather than tracking exact user identifiers. It analyzes patterns in aggregate data to estimate which marketing touchpoints are most likely to have driven conversions. This method uses non-personal signals - like device type, IP address, geographic location, time of day, and referrer data - to develop a statistical map of user journeys.
By employing techniques like logistic regression and Bayesian networks, these models connect marketing investments to shifts in revenue. For example, if increasing your Facebook ad budget by $10,000 correlates with higher sales, the model calculates the likelihood that the additional spend contributed to the revenue lift.
"Probabilistic attribution moves away from relying on existing touchpoint data. Instead, it takes a statistical approach, using probability theory to evaluate each touchpoint's contribution to conversions." – Sean Dougherty, Senior Brand Creative, Funnel
Unlike deterministic models, which rely on exact matches, probabilistic models work with confidence intervals and likelihood scores. For instance, you might see a result like "82% probability that these two interactions belong to the same household".
This statistical approach opens up opportunities but also introduces certain challenges.
Strengths of Probabilistic Attribution
One of the standout benefits of probabilistic attribution is its ability to scale and adapt. It remains effective even when cookies are deleted, devices are switched, or users browse anonymously. This makes it particularly useful for tracking cross-device journeys, such as when someone sees an ad on a smart TV but completes the purchase on a smartphone.
Another advantage is its ability to measure the impact of awareness campaigns and top-of-funnel activities - efforts that often don’t result in direct clicks. By examining changes in overall conversion patterns, probabilistic models can estimate the "halo effects" of initiatives like podcast sponsorships or YouTube pre-roll ads. Plus, since these models rely on aggregated data instead of individual identifiers, they align with privacy regulations like GDPR, CCPA, and Apple's App Tracking Transparency requirements.
While deterministic models provide exact matches, probabilistic methods trade individual precision for broader coverage, making them ideal for navigating today’s fragmented digital landscape.
Limitations of Probabilistic Attribution
Despite its advantages, probabilistic attribution has its limitations. It lacks precision at the individual level. For instance, while it might estimate that an email campaign led to 200 conversions in a month, it can’t pinpoint which specific customers were influenced.
Another challenge is that these models require substantial amounts of data to perform well. Without enough variation in marketing spend - such as across seasons, promotions, or different budget levels - the model struggles to identify clear relationships between spending and outcomes.
"Uncertainty isn't a bug, it's honesty about the limits of what any system can actually know." – Prescient AI
Additionally, the accuracy of probabilistic models can degrade over time due to changes in consumer behavior or market conditions. This phenomenon, known as model drift, means that regular updates with fresh data are essential. Continuous validation through methods like incrementality testing or geo-experiments is necessary to ensure the model remains aligned with actual business performance.
What is attribution? Attribution Models Explained - 2022 Beginner Friendly Tutorial
Main Differences Between Probabilistic and Deterministic Attribution
Deterministic models operate like a vending machine - specific inputs lead to predictable outputs. In contrast, probabilistic models are more like insurance pricing, relying on incomplete signals to estimate likelihoods. Deterministic models depend on verified identifiers, such as email addresses or user IDs, to connect an individual to a conversion. With this data, the model provides a clear yes-or-no answer.
Probabilistic models, on the other hand, use patterns from vast amounts of data to estimate the likelihood of influence. They don’t require perfect tracking but instead work with fragmented signals, such as IP addresses, device fingerprints, time-based patterns, and historical spending behaviors. These models produce confidence scores - for example, "82% probability that these two sessions belong to the same user" - rather than definitive matches.
"Deterministic models feel certain but are often wrong; probabilistic AI feel uncertain but capture reality more accurately." – Prescient AI
This difference in approach creates a fundamental trade-off. Deterministic attribution provides precise, auditable tracking, allowing marketers to pinpoint exactly which touchpoint earned credit and why. However, it can’t account for interactions it cannot directly observe, such as brand awareness campaigns or cross-device activity. Probabilistic attribution, while less precise on an individual level, offers a broader view by capturing influences and spillover effects that deterministic methods might completely miss.
The two models also fail differently. Deterministic tracking breaks down entirely if essential data is missing. Probabilistic models, however, degrade more gracefully. As data quality decreases, confidence intervals widen, but the system continues to function, albeit with reduced certainty. These characteristics make each model better suited to different marketing scenarios.
Here’s a quick comparison of their key differences:
Comparison Table
| Factor | Deterministic Attribution | Probabilistic Attribution |
|---|---|---|
| Data Requirement | Complete, clean identifiers (email, user ID) | Incomplete tracking data |
| Output Type | Binary (Yes/No) | Probability score (e.g., 85% confidence) |
| Analysis Method | Rule-based logic and SQL joins | Statistical inference and machine learning |
| Transparency | High; easy to audit | Lower; may need explainability tools |
| Flexibility | Rigid; manual updates required | Adaptive; learns from new data |
| Privacy Resilience | Low; disrupted by cookie/ID loss | High; works without user-level tracking |
| Scalability | Limited by identity/login rates | High; handles anonymous/cross-device activity |
| Primary Strength | Precision and auditability | Scale and coverage |
| Primary Weakness | Breaks without tracking | Adds uncertainty; needs ongoing validation |
These distinctions lay the groundwork for a deeper dive into the strengths and weaknesses of each approach in the next section.
Pros and Cons Comparison
When it comes to attribution models, each approach shines in specific situations but also brings along its own set of challenges. Choosing the right one often depends on your campaign goals and the type of data you have available.
Deterministic attribution is the go-to for precision. It’s easy to implement, straightforward to audit, and provides clear insights for authenticated users. But it has its limits. It oversimplifies the often-messy customer journey, struggles with privacy-related disruptions like cookie loss, and misses interactions that don’t involve digital identifiers - think awareness campaigns or podcasts.
Probabilistic attribution, on the other hand, uses statistical modeling to estimate marketing impact. It connects the dots across devices and platforms without relying on user-level IDs, giving a broader picture of your campaign’s reach. However, it’s not without its challenges. This method requires a lot of data, is more complex to set up, and introduces margins of error. Explaining its results to stakeholders expecting clear-cut answers can also be tricky.
"Deterministic attribution offers clarity inside logged-in environments, yet stops where identifiers disappear. Probabilistic attribution extends reach across devices and platforms, but replaces confirmed identity with modeled likelihood." – Emily Sullivan, Content Marketing Strategist, fusepoint
Relying solely on deterministic data can lead to last-click bias, which might cause marketers to undervalue awareness campaigns. On the flip side, probabilistic models risk over-attribution, sometimes mistaking correlation for causation. This can result in scenarios where the total attributed revenue across channels exceeds the actual revenue - sometimes by as much as 150%.
Here’s a quick side-by-side look at the strengths and weaknesses of each model:
Comparison Table
| Model | Advantages | Disadvantages |
|---|---|---|
| Deterministic | • High precision and easy auditing • Simple setup • Reliable data in authenticated environments |
• Oversimplifies customer journeys • Struggles with privacy changes and cookie loss • Misses non-digital touchpoints |
| Probabilistic | • Provides a broader view of marketing impact • Works across devices without user-level IDs • Handles privacy restrictions well |
• Complex to implement • Needs large data sets • Results include error margins • Harder to explain to stakeholders |
When to Use Deterministic Attribution
Deterministic attribution shines when user identifiers are reliably available. Its ability to directly verify interactions allows for highly accurate tracking of customer journeys.
This approach is particularly effective for SaaS and B2B companies. These businesses often deal with long buying cycles that involve multiple stakeholders. By leveraging authenticated identifiers, they can connect various interactions - like researching on mobile devices, sharing links via messaging apps, or requesting demos on desktop. In fact, account-based strategies can achieve up to 70% coverage, making it easier to track complex journeys with confidence.
E-commerce platforms with robust login systems also stand to gain. For instance, if a logged-in user clicks on a Facebook ad and later completes a purchase, deterministic tracking can confirm the exact path they took. Businesses that prioritize authentication - whether through apps, gated content, or member-only portals - are well-positioned to maximize the benefits of deterministic attribution. However, reliance on guest checkouts tends to lower match rates. For companies where user authentication is a core part of the business model, this method offers high-accuracy tracking tailored to their needs.
Best Applications
Some industries are especially well-suited to deterministic attribution due to its strengths.
- Retail media networks: Loyalty program IDs make it possible to directly link digital ad exposure to in-store purchases. For example, when a point-of-sale system captures identifiers like hashed email addresses used in online campaigns, it enables precise tracking of offline-to-online journeys.
- Compliance-focused industries: These sectors often require clear, auditable data for every conversion. Deterministic models deliver the transparency needed to meet these strict requirements.
Marketing teams often report a positive return on investment with deterministic attribution when match rates exceed 30%. While deterministic tracking typically covers 30–60% of total traffic, it offers over 95% accuracy for matched users. This makes it a reliable choice for businesses operating in authenticated environments.
That said, while deterministic attribution provides unmatched precision in certain contexts, its limitations in guest or anonymous scenarios underscore the importance of combining it with probabilistic attribution for more fragmented customer journeys.
When to Use Probabilistic Attribution
Probabilistic attribution is a go-to method when user identifiers are limited or unavailable. This often happens in privacy-focused environments shaped by regulations like GDPR and CCPA, or when users browse anonymously, clear their cookies, or use ad blockers. Unlike deterministic models that depend on exact identifiers, probabilistic systems adapt when identifiers are sparse - confidence intervals adjust instead of causing complete tracking failures.
One of the standout use cases for probabilistic attribution is cross-device fragmentation. Imagine a customer sees an ad on a Smart TV but later makes a purchase on their phone or laptop. Without shared logins to connect these interactions, deterministic models struggle. Probabilistic attribution steps in by using tools like household IP ranges, device fingerprinting, and time-window modeling to piece together these fragmented journeys. This capability makes it the preferred method for Connected TV (CTV) measurement, where shared household devices are often involved in viewing, but purchases happen on personal ones. This ability to link devices seamlessly also makes probabilistic attribution highly effective for large-scale campaigns.
"Probabilistic attribution scales where deterministic cannot." - Emily Sullivan, Content Marketing Strategist, fusepoint
High-volume campaigns are another area where probabilistic models excel. These systems analyze aggregate data to identify patterns, such as how a $10,000 investment in one channel affects revenue across others. This approach captures the 30–50% of customer journeys that deterministic tracking misses, offering broader insights in environments where user-level tracking is limited or fragmented. While deterministic attribution provides precision, probabilistic models fill the gaps, making them indispensable for marketers dealing with incomplete data.
This adaptability makes probabilistic attribution particularly useful for high-volume and upper-funnel marketing strategies.
Best Applications
Certain industries and scenarios are especially suited to probabilistic attribution. E-commerce and direct-to-consumer (DTC) brands use it to track customer journeys that span mobile apps, desktop browsing, and social media. Omnichannel and scaling brands with large datasets rely on these models for identifying patterns across multiple channels.
Upper-funnel awareness campaigns - like podcasts, YouTube ads, and display ads - are another prime area for probabilistic attribution. These channels often drive influence over time rather than generating immediate clicks. For example, a YouTube campaign might lead to a 15% increase in branded search volume two weeks after launch, an effect deterministic last-click models would overlook entirely. Similarly, platforms like TikTok and Snapchat, which often produce view-through rather than click-through conversions, benefit greatly from probabilistic models that can capture their true impact within the marketing funnel.
Probabilistic attribution is also invaluable when dealing with view-through conversions and delayed customer actions. These models assign likelihood scores, such as an 82% probability that two interactions came from the same household. While this approach provides actionable insights even without exact user tracking, it’s important to validate the results. Techniques like geo-experiments or holdout tests can help ensure that the correlations identified by probabilistic models reflect actual campaign lift.
How to Choose Between Probabilistic and Deterministic Models
Decision Framework
Selecting between probabilistic and deterministic models depends on the quality of your data and your specific business needs. Begin by evaluating your data: deterministic models work best when you have complete user identifiers, like email addresses or user IDs. However, if tracking data is incomplete or lost, deterministic attribution falls short. Probabilistic models, on the other hand, can handle noisy or fragmented data by leveraging statistical inference. While they remain functional even with lower-quality data, their confidence intervals grow wider as data quality decreases.
Privacy regulations and technical capabilities also play a critical role. For industries like healthcare or finance, where compliance with GDPR, CCPA, or HIPAA is essential, deterministic models provide the clear audit trails these regulations demand. However, updates like iOS 14.5, which allow users to opt out of tracking, have made deterministic models less effective for mobile app attribution. Probabilistic models, which don’t rely on persistent user-level tracking, excel in privacy-focused environments. The trade-off? They require advanced statistical expertise, while deterministic models are easier to implement with basic SQL skills.
As Danika Rockett, Content Marketing Manager at RudderStack, explains:
"Deterministic models offer precision and auditability. Probabilistic models handle incomplete data and adapt over time. The best teams often use both."
Your business objectives should ultimately guide your decision. Deterministic models are ideal when certainty is non-negotiable, such as verifying financial transactions. Probabilistic models, however, are better suited for tasks like recognizing patterns in awareness campaigns or personalizing content for anonymous users. A hybrid approach often works best: start with deterministic methods for users with identifiable data, then expand coverage with probabilistic techniques for anonymous or cross-device interactions. If you're considering a probabilistic model like Marketing Mix Modeling, ensure your historical data includes enough variation in spend levels to accurately estimate relationships between spend and revenue.
For regulated industries, it's essential to document confidence thresholds and use explainability tools, such as SHAP values, to make attribution decisions more transparent. Many marketers now combine both approaches - using "triangulation" with Marketing Mix Modeling, multi-touch attribution, and incrementality testing - to get the most accurate insights into marketing performance.
Conclusion
Main Takeaways
Grasping the distinction between probabilistic and deterministic attribution models is essential for making informed, privacy-conscious marketing choices. Deterministic models rely on exact identifiers, making them highly effective in environments like subscription platforms, loyalty programs, or CRM-linked email campaigns where user identity is consistently authenticated. However, their precision can sometimes be misleading, as they fail to account for untracked touchpoints.
On the other hand, probabilistic models use statistical methods to estimate the influence of various touchpoints in fragmented customer journeys. These models shine in areas like upper-funnel awareness, Connected TV (CTV), cross-device interactions, and anonymous web sessions where direct identifiers are unavailable. While they include confidence intervals and acknowledge a margin of error, they often provide a more realistic picture than rigid, rule-based systems. As Prescient AI aptly states:
"Deterministic models feel certain but are often wrong; probabilistic AI feel uncertain but capture reality more accurately".
The rise of privacy regulations such as GDPR and CCPA, alongside technical shifts like iOS 14.5 updates and the phasing out of third-party cookies, has pushed marketers toward probabilistic methods. Deterministic approaches are losing reliability as users increasingly opt out of data sharing and platforms impose stricter limits. In contrast, probabilistic models adapt well to these constraints, working effectively even with limited user identifiers.
A balanced, triangulated approach can help bridge the gap between these methodologies. Combining tools like Marketing Mix Modeling, multi-touch attribution, and incrementality testing allows marketers to validate insights from multiple angles. Deterministic attribution works best in environments with strong user authentication, offering certainty and auditability. Meanwhile, probabilistic models are ideal when scale and comprehensive coverage are critical, particularly for measuring the broader impact of awareness campaigns. Ultimately, attribution should serve as a guide for decision-making rather than an absolute measure.
FAQs
How do I know if my match rate is high enough for deterministic attribution?
To achieve reliable deterministic attribution, your match rate needs to be over 95%. Deterministic models rely on precise identifiers such as email addresses, user IDs, or device IDs. A high match rate ensures these models can deliver accurate and dependable results.
How accurate is probabilistic attribution, and how should I interpret confidence scores?
Probabilistic attribution relies on statistical algorithms to estimate the relationship between touchpoints and conversions, rather than directly verifying these connections like deterministic models do. It introduces a level of uncertainty, represented by confidence scores. For instance, a confidence score of 70% suggests there's a 70% chance the attribution is correct, leaving room for some doubt. While higher confidence scores typically indicate greater reliability, they don’t ensure complete accuracy.
What’s the simplest way to combine deterministic and probabilistic attribution without double-counting?
To merge deterministic and probabilistic attribution effectively while avoiding double-counting, consider a hybrid approach. Begin by using deterministic data to assign conversions, as it provides precise and reliable results. For touchpoints without clear identifiers, apply probabilistic models to estimate their contributions.
To maintain accuracy, establish clear attribution rules that distribute credit based on the quality or confidence level of the data. This method ensures thorough coverage while safeguarding the integrity of your data.


